

The initial wave of generative AI was defined by the “slot machine” effect. You entered a text prompt, pulled the lever, and hoped the latent space returned something usable. For hobbyists, this randomness was part of the charm. For professional creators and marketers, it was a bottleneck. Relying on text-to-video tools often meant losing control over character consistency, lighting, and composition.
The industry is now shifting toward a more disciplined approach: the image-first pipeline. By establishing a high-fidelity still image before introducing motion, creators can lock in the visual DNA of a project. This workflow centers on the use of Image to Video AI technology to bridge the gap between static concept art and dynamic content.
The Logic of the Image-First Pipeline
The primary challenge in generative video is “hallucination.” When an AI generates a video from text alone, it has to invent the subject, the environment, and the motion simultaneously. This often leads to “shimmering” textures or subjects that morph into different shapes mid-frame.
Starting with a still image changes the mathematical problem. The AI is no longer guessing what the subject looks like; it is calculating how that specific subject should move through 3D space. This is where Image to Video AI becomes a foundational tool in the creator’s stack. It allows for a separation of concerns: use an image generator or a real photograph to handle the “what,” and use the video model to handle the “how.”
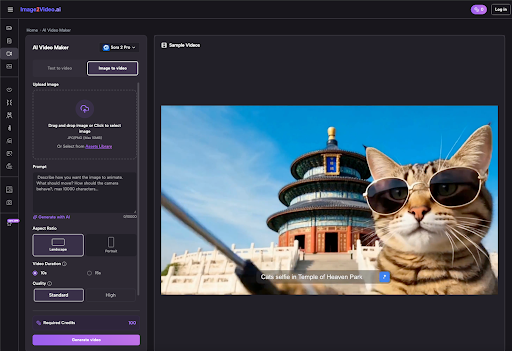
Phase One: Generating the Hero Asset
In a professional workflow, the “Hero Asset” is the primary still image that dictates the color palette, lighting, and character details.
Defining Composition and Aspect Ratio
Before hitting generate, a creator must determine the final distribution channel. Traditional text-to-video tools often default to a square 1:1 ratio, but a tool-savvy operator knows that cropping a video after the fact results in a loss of resolution and poor framing.
Using an AI image generator, you can specify ratios like 16:9 for cinematic projects or 9:16 for social media platforms. By generating the image at the native ratio of the intended output, you ensure that the motion vectors calculated later align perfectly with the boundaries of the frame. This reduces the risk of the AI “filling in” edges with blurry or nonsensical textures.
Prompting for Motion Potential
Not all images are created equal when it comes to animation. A flat, architectural drawing is harder to animate realistically than a scene with depth. Creators are finding success by generating images with a clear “foreground-midground-background” structure. When you eventually apply Photo to Video techniques, the AI can more easily distinguish which layers should move and which should remain static, creating a more convincing parallax effect.
Phase Two: The Transition to Motion
Once the hero image is finalized, it is uploaded into the video generator. This is where the technical parameters become critical for a repeatable output.
Managing the Seed and Consistency
The “Seed” is a numerical starting point for the AI’s noise generation. In a repeatable workflow, keeping track of the seed is essential. If you find a specific motion style—such as a slow cinematic zoom or a gentle hair-flip—that works for your brand, recording that seed allows you to replicate the “feel” across multiple different images.
The Role of Descriptive Motion Prompts
Even though you are providing a visual reference, the text prompt still plays a secondary role. Instead of describing the subject (which the image already provides), the prompt should focus on the physics of the scene. Phrases like “flowing water,” “dynamic lighting shifts,” or “cinematic pan left” act as instructions for the motion engine.
While Photo to Video AI models have become significantly more intuitive, it is important to acknowledge a current limitation: the AI still struggles with complex, multi-step physical interactions. For example, asking the AI to show a character tie their shoelaces or perform a complex card trick often results in anatomical distortions. The current sweet spot for this technology lies in atmospheric motion rather than complex mechanical tasks.
Specialized Modules: Effects and Human Interaction
Modern workflows are moving beyond simple animation and into specialized behavioral modules. Systems like Image2Video.ai have introduced specific “effects” that target common creator needs.
Social Media and Human Effects
Specific modules for actions—such as the AI Kiss, AI Hug, or AI Dance—are designed to solve the problem of human interaction. Historically, AI has struggled to show two subjects touching without them merging into a single blob of pixels. Specialized models are trained on specific motion paths to ensure that the integrity of both subjects is maintained.
Animate Old Photos and Heritage Projects
There is also a growing sector for Photo to Video AI in the realm of archival work. Animating historical photos requires a different level of restraint. Over-animating a 1920s portrait can make it look like a modern deepfake, losing its historical weight. A practical operator uses subtle motion—a blink, a slight head tilt—to breathe life into the photo without overwriting the original’s character.
Integration into Marketing and Production
For a marketing team, the goal is rarely a single video. The goal is a campaign. This is where the image-first pipeline proves its efficiency.
- Asset Templating: A brand can generate 50 variations of a product shot using an AI image maker.
- Batch Animation: Those 50 images are run through a Photo to Video converter with a consistent motion prompt.
- Cross-Platform Deployment: Because the aspect ratios were set at the image stage, the team has a library of 16:9, 9:16, and 1:1 videos ready for YouTube, TikTok, and Instagram without manual re-editing.
This “Batch and Scale” approach is only possible when the workflow is decoupled from the chaos of text-only generation.
The Reality Check: Current Technical Limitations
It is a mistake to view these tools as a “set and forget” solution. Visible caution is necessary when planning high-stakes projects.
Temporal Consistency and Noise
One of the primary hurdles remains temporal consistency. In longer generations, the background of a video may begin to shift or “drift” away from the original hero image. This is why most professional AI creators currently work in short, 3-to-5-second bursts. These clips are then stitched together in traditional NLE software (like Premiere Pro or DaVinci Resolve). Expecting a generative tool to produce a coherent 60-second narrative in a single pass is currently unrealistic.
The Resolution Gap
While image generators can produce 4K-quality stills, the video versions often require upscaling. The computational load of generating 24 or 30 frames per second at high resolution is immense. Creators should expect an extra step in their pipeline involving AI upscalers to bring the video quality up to modern broadcast or social standards.
Setting Up for Success: A Practical Checklist
If you are integrating these tools into a professional environment, follow this sequence to minimize wasted compute time:
Finalize the Still First: Never move to the video stage until you are 100% satisfied with the lighting and composition of the hero image.
Check the Edges: Ensure the subject is not too close to the edge of the frame. The AI needs “room” to move the camera or the subject without hitting the frame boundary.
Use High Contrast: Images with clear lighting cues (rim light, shadows) provide the AI with better depth information, leading to more realistic motion.
Set Visibility: If you are working on proprietary brand assets, ensure the “Public Visibility” setting is toggled to private to protect your intellectual property.
The Future of the Image-to-Motion Stack
The trajectory of generative media is clear: more control, less randomness. As tools like the Image2Video.ai suite continue to refine their motion engines, the line between traditional cinematography and generative art will continue to blur.
The image-first pipeline is more than just a workaround for current AI limitations; it is a return to traditional production values. It treats the AI as a digital camera and a physics engine rather than a magic wand. For the creator who values precision, mastering the transition from a static frame to a moving sequence is the most valuable skill set in the current landscape. By focusing on the “Hero Asset” and applying intentional motion, you transform AI from an unpredictable toy into a repeatable, professional-grade production engine.


